记录一次曲折得高并发调优案例
原创文章,禁止转载,作者保留追究版权的权利。
某日上午,自监控,dsp服务器6.199负载异常,同时有同事反馈DSP平台领数异常,登录服务器一看load average 40多,
1、使用netstat查看,TIME_WAIT到了6W多,于是呼打开了tcp_tw_recycle和tcp_timestamps两个参数,实现TIME_WAIT的快速回收,不到10分钟,TIME_WAIT数量从6W多降到了3000左右,负载也下来了,平台响应也上去了,调优也算是大功告成。普天同庆,皆大欢喜。
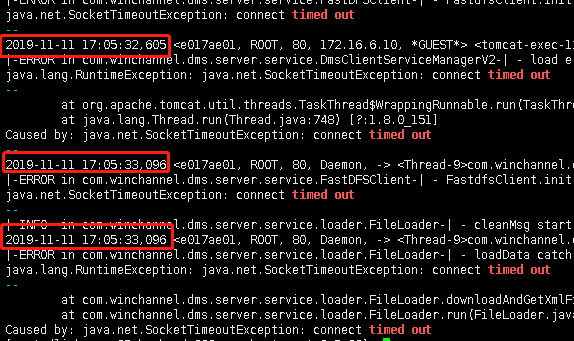
2、好景不长,随后的几天,同架构内其他服务器相继出现如下图的报错,
我也不是特别懂JAVA,如此问题困惑了我们开发人员好久,差不多有半个来月吧,后来,我把所有日志拿下来做了一个线性的分析,发现该错误出现的时间,刚好是调优后,然后就沟通了开发的同事,在这个时间点程序上,有没有做过升级什么的,得到了否定的答案。
3、当时调优修改过有几个参数,我也不确定是哪个参数影响了这个,本能的想到了tcpdump,开始行动,抓了几十M的包(并发很高,只需要几十秒,就几十M了)然后找连接异常的,发现有好多tcp-retransmission,这种TCP重传,一般意义上会被理解为网络波动,当然我也是这样想的,于是加强了对网络间的监控,做到毫秒级监控,过了两个小时,网络正常,报错依旧。
4、于是乎开始双向抓包,然后发现了一规律,只要是从LB过来的包TCP时序是递增的就可以正常完成SYN,而时序非递增就被拒绝了。
5、发现这一个问题基本就可以定位问题了,因为我们打开 tcp_tw_recycle和tcp_timestamps两个参数 会导致内核对TCP时序做校验,但如果再关上这两个参数,那TW又几万了,负载又上去了,又踏上了翻内核参数的漫长之路。kernel.org wiki走起。
6、在茫茫参海中,终于找到了似乎可以解决我的问题的参数tcp_max_tw_buckets,既然不能快速回收,我可不可以做个限制,于是tcp_max_tw_buckets就出场了,设置成了6000,6000以上的,就自动丢,自然是不错的选择,然后把 tcp_tw_recycle和tcp_timestamps两个参数 又取消了。
7、设置完成观察了3个小时发现负载并没有飚上去,但此前的JAVA报错已经消失了。
8、问题始末,因为我是所有服务器同时打开了 tcp_tw_recycle和tcp_timestamps两个参数 按理说,不应该存在时序混乱的问题,于是自己搭了个测试环境继续找原因,最终找到了罪魁祸首,原来是LB服务器,因为包在后端发出时,是有时序的,但经过LB服务器后,会被LB服务器重新封装,时序再次被打乱。
结论:如果架构中存在了NAT或LB及其他高并发负载架构,就不要开 tcp_tw_recycle和tcp_timestamps两个参数 了,可以使用 tcp_max_tw_buckets 来限制TW数量达到有效控制负载的同时,也不会引发JAVA丢连接。